上一篇,顺着云计算的发展史,我们看到了兴起于 PaaS 技术普及的容器技术,看到了容器技术通过容器镜像彻底解决了打包问题,按照连续思维,其实接下来应该讲讲 Docker 出现之后有哪些竞争对手,为什么 Docker 可以胜出,连带着让 Docker 几乎等同于容器技术本身,容器编排竞争中 Swarm 为什么输给了 Kubernetes,不过出于个人对整个云原生知识网络的感受,我觉得可以在这次开个分支,先不谈历史,讲一下 Docker 的实现原理。
本文主要是解释 Docker 沙盒的工作原理,回答诸如但不限于以下问题:
- 为什么容器里只能跑“一个进程”?
- 容器和虚拟机有什么区别?
隔离魔术:Linux NameSpace
什么是 Linux NameSpace
Linux Namespace是Linux提供的一种内核级别环境隔离的方法,可以提供多种类别的环境隔离赋能,下面我们以 PID NameSpace 为例,看看容器是怎么样应用 Linux NameSpace 来构建独立的环境的。
Linux下的 root 进程的PID是 1,NameSpace 可以提供一种机制,让 NameSpace 内部的其他进程认为主进程的 PID 是 1,不同 NameSpace 之间的进程无法看到彼此。
执行docker run -it busybox /bin/sh,这句命令的具体作用是,启动一个busybox镜像的容器,在容器中执行 /bin/sh,并直接进入容器中。
1 | [root@master ~]# docker run -it busybox /bin/sh |
然后我们在容器中运行 ps 命令查看进程
1 | / # ps |
可以清晰地看到,容器中一共就两个进程,我们启动的 /bin/sh 为 1 号进程,ps 的进程为 2 号进程,这两个进程已经被隔绝到了跟宿主机不同的单独空间中。
而这就是 NameSpace 做的工作。
除了进程 ID 隔离(PID Namespace)之外,Linux NameSpace 还提供了多种隔离种类:
| 分类 | 系统调用参数 | 相关内核版本 |
|---|---|---|
| Mount namespaces | CLONE_NEWNS | Linux 2.4.19 |
| UTS namespaces | CLONE_NEWUTS | Linux 2.6.19 |
| IPC namespaces | CLONE_NEWIPC | Linux 2.6.19 |
| PID namespaces | CLONE_NEWPID | Linux 2.6.24 |
| Network namespaces | CLONE_NEWNET | 始于Linux 2.6.24 完成于 Linux 2.6.29 |
| User namespaces | CLONE_NEWUSER | 始于 Linux 2.6.23 完成于 Linux 3.8 |
而容器环境,就是对这些隔离种类的复合使用的结果,具体的调用测试可以参照“左耳朵耗子”大佬在多年前的一篇文章《DOCKER基础技术:LINUX NAMESPACE(上)》,调用文档可以参考官方文档。
Linux NameSpace 的优势(对比虚拟机)
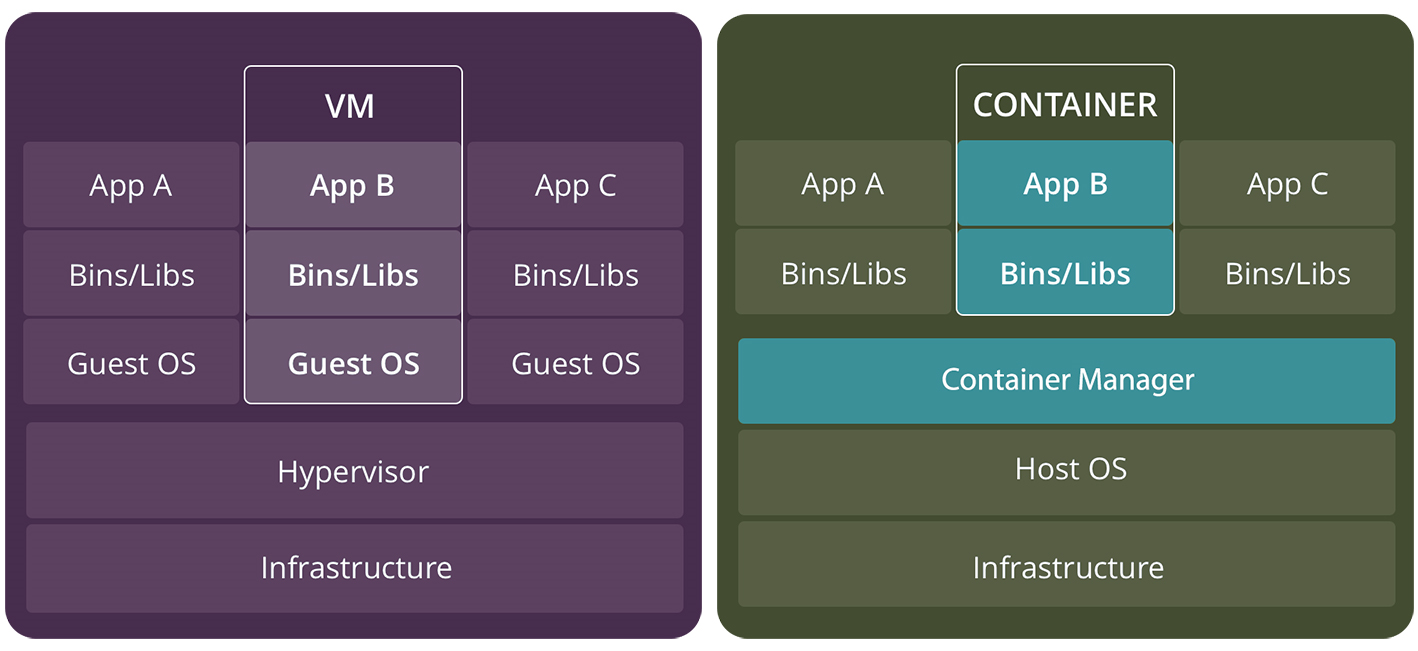
上图是网上常见的虚拟机和容器的对比通,把容器管理系统放到了跟虚拟系统一个级别,实际是有问题的,我们对它做一下纠正。
如上图所示,因为容器的本质其实就是 Linux 系统上的原生进程做了特殊的隔离措施,对容器的操作其实都是原生物理机操作系统的进程操作,没有中间的性能损耗。而虚拟机自身都是完整的操作系统,本身就要占用不小的内存,用户程序运行在虚拟机内部,对宿主机的计算资源、网络和磁盘 I/O 的调用必须要经过虚拟化软件的拦截和处理,性能损耗很大。
故而容器启动要比虚拟机快很多,性能也是要比虚拟机更高,概括一下,即“敏捷”和“高性能”,这是容器技术在 PaaS 时代大行其道的重要原因。
。
Linux NameSpace 带来的问题(对比虚拟机)
Linux NameSpace 的隔离并非只有好处,有利就有弊,主要的问题有以下两点。
1. 隔离的不彻底。
2. 有一些资源和对象无法被隔离。
隔离的不彻底
尽管我们可以在容器里通过 Mount Namespace 单独挂载其他不同版本的操作系统的 rootfs 文件,比如 CentOS 或者 Ubuntu 等各种 Linux 发行版,但这并不能改变共享宿主机内核的事实。这意味着,如果你要在 Windows 宿主机上运行 Linux 容器,或者在低版本的 Linux 宿主机上运行高版本或者低版本的 Linux 容器,都是行不通的。
而相比之下,拥有硬件虚拟化技术和独立 Guest OS 的虚拟机就要方便得多了。最极端的例子是,Microsoft 的云计算平台 Azure,实际上就是运行在 Windows 服务器集群上的,但这并不妨碍你在它上面创建各种 Linux 虚拟机出来。
有一些资源和对象无法被隔离
一个很经典的例子就是时间,如果在容器中调用 settimeofday 更改了时间,那么就会对宿主机以及所有宿主机上的容器造成影响,所以在生产环境中,没有人敢把运行在物理机上的容器直接暴露到公网上。
而虚拟机虚拟化的是完整的操作系统,完全不存在这样的顾虑。
当然,现在其实出现了一些基于虚拟化或者独立内核技术的容器实现,可以比较好地在隔离与性能之间做出平衡,后续我们也会对这种方案做一些介绍和实践。
限制大法:Linux Cgroups
在使用了 NameSpace 做隔离之后,“容器”已经被创建出来了,但是当前被隔离的进程是完全没有做任何限制的,能够使用到100% 的物理资源,如内存、CPU等,这显然不符合我们的需求。
Linux Cgroups 就是我们用来对进程(组)做限制的系统能力。
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
此外,Cgroups 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。
下面我们做一个试验,亲自操作一下 Cgroups 的限制能力。
在 Linux 中,Cgroups 暴露给用户的操作接口是文件系统的形式存在的,它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下,使用 mount 命令可以将它展示出来。
1 | [root@master ~]# mount -t cgroup |
这些诸如 cpuset、cpu、 memory 这样的子目录就是这台机器当前可以被 Cgroups 进行限制的资源种类。在对应的资源种类下,可以看到该类资源具体可以被限制的方法。
1 | [root@master ~]# ls /sys/fs/cgroup/cpu |
下面我们尝试使用 Cgroups 对自己运行的进程做限制。
写一个死循环程序,命名为 test.c,然后用 gcc 编译
程序源码:
1 |
|
操作:
1 | [root@master cpu]# cd ~/ |
随后运行程序并使用 top 命令查看程序占用:
1 | [root@master ~]# nohup ./test & |
可以看到,我们的测试程序启动后 PID 为 136487 ,它在启动后几乎无节制的占用了 CPU 的 97% 左右。
下面我们使用 Cgroups 对它做一些CPU限制:
1 | [root@master ~]# cd /sys/fs/cgroup/cpu/new_test/ |
实验完成。
而 docker 的 Cgroups 组其实就在 /sys/fs/cgroup/…/docker/…/ 下。
总结
综上所述,一个正在运行的 Docker 容器,其实就是启用了多个 Linux Namespace 的,受 Cgroups 配置的限制的应用进程。
然后我们就能自然而然的得出另一个结论,容器是一个“单进程”模型。

